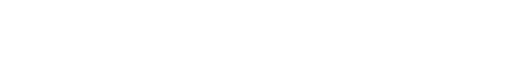Building floor plans with locations of safety, security and energy assets such as IoT sensors,
thermostats, fire sprinklers, EXIT signs, fire alarms, smoke detectors, routers etc. are vital for
climate control, emergency security, safety, and maintenance of building infrastructure. Existing
approaches to building survey are manual, and usually involve an operator with a clipboard and
pen, or a tablet enumerating and localizing assets in each room. In this paper, we propose an
interactive method for a human operator to use an app on a smart phone to (a) create the 2D
layout of a room, (b) detect assets of interest, and (c) localize them within the layout. We use
deep learning methods to train a neural network to recognize assets of interest, and use human in
the loop interactive methods to correct erroneous recognitions by the networks. These
corrections are then used to improve the accuracy of the system over time as the inspector moves
from one room to another in a given building or from one building to the next; this progressive
training and testing mechanism makes our system useful in building inspection scenarios where a
given class of assets in a building are same instantiation of that object category, thus reducing the
problem to instance, rather than category recognition. The experimental characterization of this
method are included in [1].
Asset Detection
One major shortcoming in this approach is the latency between a human correction and the
model’s ability to reflect the new information. In choosing a more traditional learning approach
for asset classification, the model requires long training sessions in order to update its weights to
incorporate the newly collected information. This training process could take hours or even days
as the training data grows. In a new environment, where the assets in the building do not
resemble assets previously seen in the training data, the human operator finds himself or herself
correcting the categorization of the asset very often.
We have recently proposed a method which reduces this training time by up to a factor of 10 and
improves performance accuracy so the operator will not need to intervene frequently. To do so,
we use a Neural Turing Machine (NTM) [2] architecture, a type of Memory Augmented Neural
Network (MANN) [3], with augmented memory capacity that allows us to rapidly incorporate
new data to make accurate predictions after only a few examples, all without compromising the
ability to remember previously learned data. This architecture lends itself nicely to the problem
at hand: The NTM combines the ability to slowly learn abstract representations of raw image
data, through gradient descent, with the ability to quickly store bindings for new information,
after only a single presentation, by utilizing an external memory component. This combination
enables us to tackle both a long-term category recognition problem where we can identify 10
different classes of objects across different buildings as well as an instance recognition problem
where the model can quickly learn to recognize a particular never-before-seen instance of an
asset as belonging to a certain category. Whereas in [1], the operator is required to retrain the
model on all the collected data before the performance reflects the added information, now the
new information is assimilated almost instantly and can be robustly trained later to be reflected
in a long-term capacity. This approach, allows us to rapidly incorporate new data into our
model, improving prediction accuracy after only a few examples, without compromising its
ability to remember previously learned data. It also reduces the training time needed to update
the model between building survey sessions.
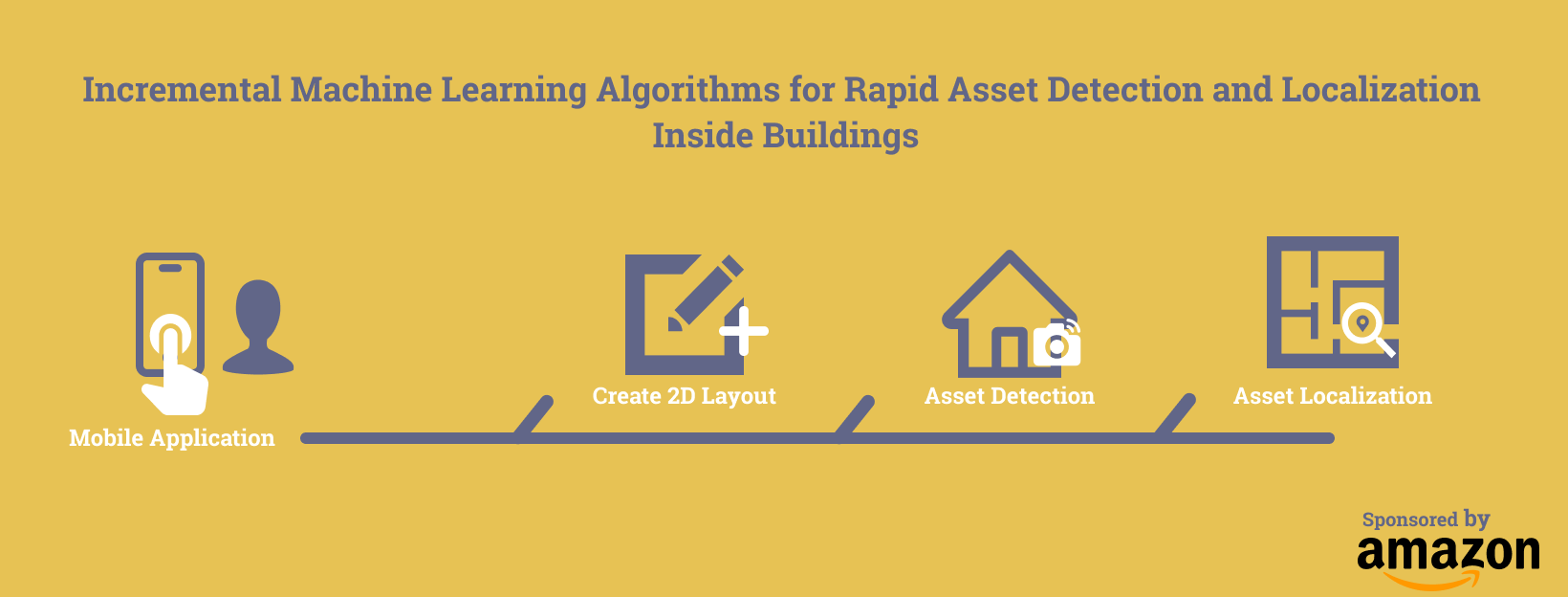
The NTM architecture consists of two major components, a neural network controller and a memory bank. The NTM model is depicted in Fig. 1.
Figure 1: Block Diagram of Neural Turing Machine;
It consists of a controller, such as a feedforward network or LSTM, which interacts with an external memory module using read and write heads [2]. At every step, the controller network receives inputs from the external environment and emits outputs in response. It also reads to and writes from a memory matrix via a set of parallel read and write heads [2]. Most importantly, every component is differentiable, including the read and writes to memory. This is accomplished via “blurry” read and write operations that interact to a greater or lesser degree with all the elements in memory. Because of the differentiability, the weights of the entire model can be updated via backpropagation. Memory encoding and retrieval in a NTM external memory module is rapid, with vector representations being placed into or taken out of memory potentially every time-step. This ability makes the NTM a perfect candidate for meta-learning and low-shot prediction, as it is capable of both long-term storage via slow updates of its weights, and short-term storage via its external memory module. Thus, if a NTM can learn a general strategy for the types of representations it should place into memory and how it should later use these representations for predictions, then it may be able use its speed to make accurate predictions of data that it has only seen once.
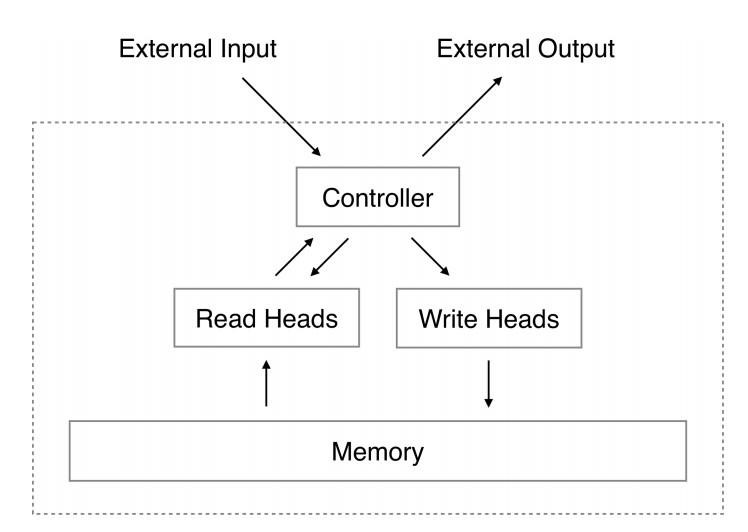
We now provide more details on the specific way in which we adapted the NTM architecture to the object detection problem. Fig. 2 visualizes how the inputs to the controller are used. At time t, the controller receives a 921,614-dimensional vector consisting of 640 × 480 pixel raw image x(t), one-hot encoded class label y (t-1), and bounding box coordinates b(t-1). The controller crops the raw image using object localization. This 400 x 400 pixel cropped image, is passed into the LSTM and a key representation, k(t), is outputted. This key is used to read memory r(t) from the memory matrix, M(t). A soft-max classifier uses the memory, r(t), to make a class prediction, y (t) for the input image. The raw image, key, and class prediction are passed as additional inputs to the following time step of the LSTM. Meanwhile, the true label, y(t-1), and bounding box information, b(t-1), at time t are used in combination with the additional inputs (x(t-1), k(t-1), y (t-1)) from the previous time step to compute the cross entropy loss for that particular class prediction using prediction y (t-1) and ground truth y(t-1). This loss is used to update the weights of the LSTM via backpropagation. Additionally, we update the sample representation-class binding for class y(t-1) by writing to memory.
Figure 2: NTM transition from time t to time t+1 for the asset/object detection problem;
We have shown that the NTM architecture described above allows us to rapidly incorporate new data into our model, improving prediction accuracy after only a few examples, without compromising its ability to remember previously learned data. This approach reduces the training time needed to update the model between building survey sessions by up to a factor of 10 [4]. Experiments show that our proposed method outperforms by as much as 15% the prediction accuracy attained by using more traditional batch processing deep learning methods where new data is combined with all old data to train the model. The advantage is especially pronounced for assets in never-before-seen buildings.
References:
R. Kostoeva, R Upadhyay, Y. Sapar, and A. Zakhor, “Indoor 3d interactive asset detection
using a smartphone,” in ISPRS, 2019, Indoor 3D workshop.
Alex Graves, Greg Wayne, and Ivo Danihelka, “Neural turing machines,” CoRR, vol.
abs/1410.5401, 2014.
Adam Santoro, Sergey Bartunov, Matthew Botvinick, Daan Wierstra, and Timothy P.
Lillicrap, “One-shot learning with memory-augmented neural networks,” CoRR, vol.
abs/1605.06065, 2016.
A. Balamurugan and A. Zakhor , "Online One-shot Learning for Indoor Asset
Detection" Machine Learning for Signal Processing (MLSP) workshop, Pittsburgh, PA,
October 2019 [Adobe PDF]